3.5 KiB
Проектирование схемы БД
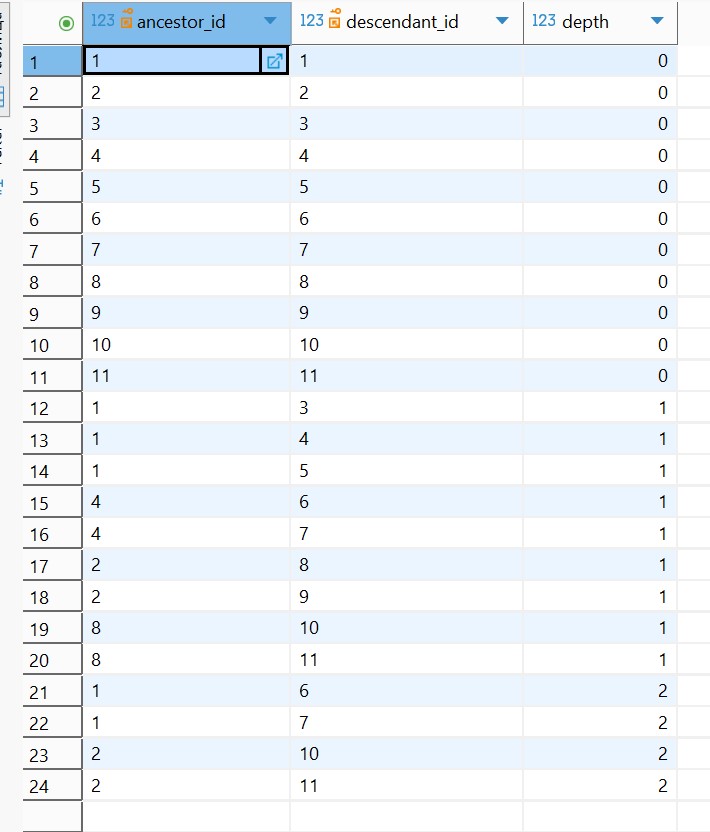
Поставленную задачу можно решить 3 основными подходами: Closure Table, Nested Sets, Adjacency List.
Я выбрал Closure Table (таблица замыканий), так как он обеспечивает простые и
быстрые запросы к поддеревьям категорий независимо от глубины вложенности.
В любом запросе к дереву я могу обойтись обычным JOIN по таблице связей
category_closure, без рекурсивных CTE и сложной логики в SQL. Это даёт
предсказуемую производительность на больших иерархиях и хорошо масштабируется
при росте количества уровней и категорий. Дополнительно, Closure Table
позволяет так же просто получать не только потомков, но и всех предков
узла (например, для хлебных крошек) через тот же механизм. Структура
данных при этом остаётся реляционной и хорошо индексируемой: по предку
ancestor_id и по потомку descendant_id. Операции изменения структуры
(добавление, перемещение, удаление узлов) сложнее, чем при простом parent_id,
но их можно инкапсулировать в функции/процедуры и вызывать как единый API.
В реальном каталоге товаров такие изменения происходят значительно реже, чем
чтение каталога и выборка товаров по разделам, поэтому увеличение стоимости
изменений логично обменять на ускорение чтения.
Таким образом, Closure Table лучше всего соответствует требованиям:
- произвольная глубина дерева,
- быстрый доступ к поддеревьям
- приемлемая стоимость редких операций изменения структуры категорий.
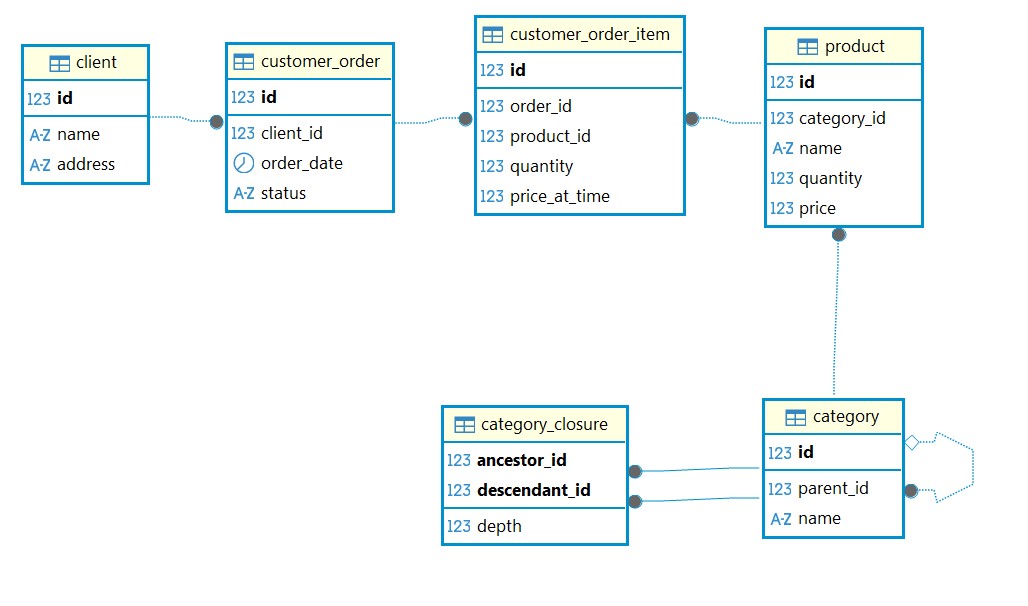
Диаграмма БД
Примеры данных в таблицах
Покупатели

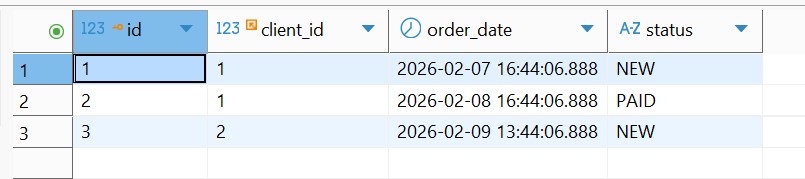
Заказы
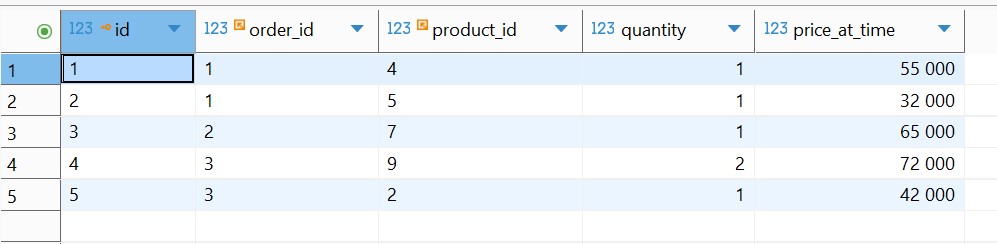
Позиции заказа
Номенклатура (товары)
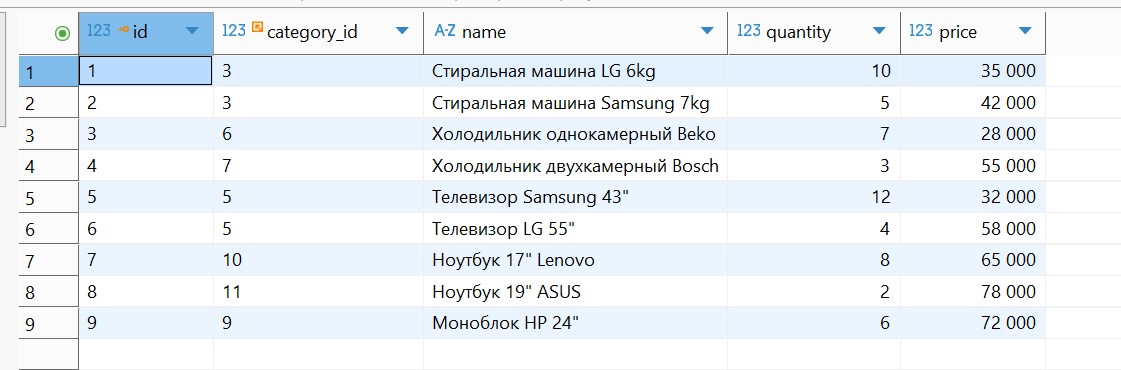
Категории
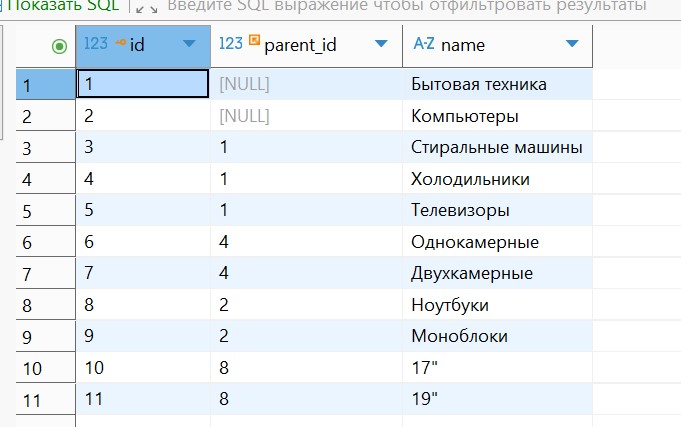
Closure Table для категорий